No Vibes Allowed
“The only way to get better output from an LLM is to put better tokens in.”
I was exploring the sets and sub-sets in the Context Engineering but what a coincidence that I never thought about ‘Context Engineering’ itself. So this time I started learning about it. And it landed very differently than what I thought.
The premise isn’t “use better models” or “write better prompts.” The premise is that the problem is upstream of both. It’s about what you put in front of the model in the first place.
The Part Nobody Talks About
Here’s the counterintuitive thing about context windows: more isn’t better.
~170k tokens sounds like plenty. But the relationship between context usage and output quality isn’t linear. Past a certain point — roughly 40% capacity — quality drops noticeably.
Dex (CEO HumanLayer) calls this the Dumb Zone.
Load up a session with file searches, JSON tool responses, stale documentation, and half a dozen MCP connections and you’re working in it. The model is technically reading everything. Its effective reasoning isn’t intact.
The goal isn’t to use as much context as possible. It’s to stay under 40% with exactly the right information.
Which immediately reframes the question. It’s not “how do I give the agent more?” It’s “how do I give it only what it needs?”
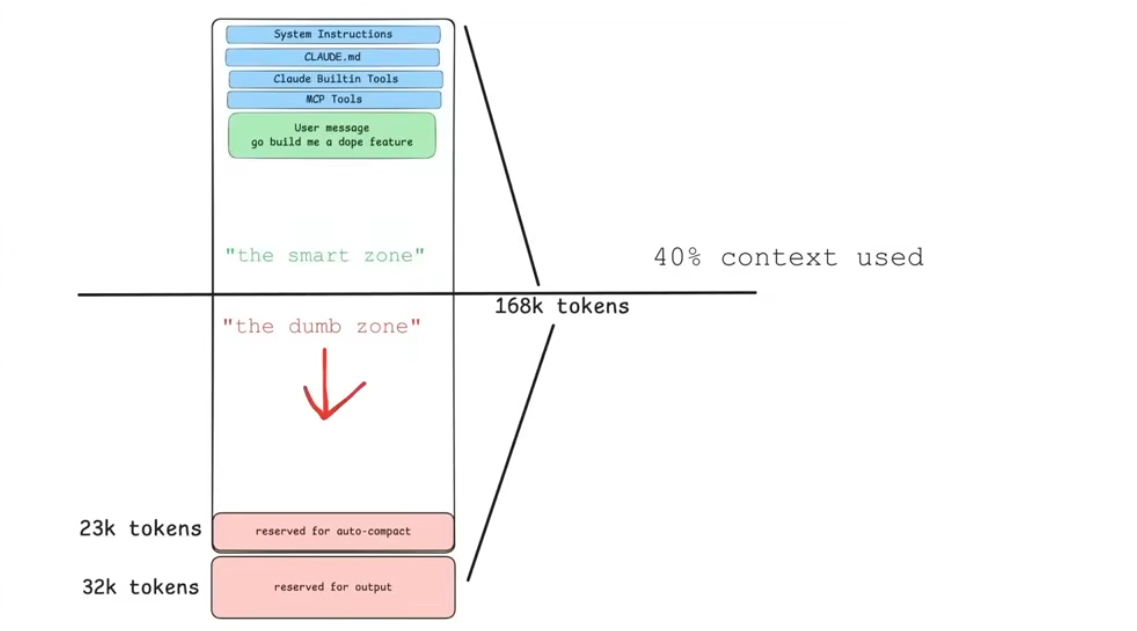
NOTE: 40% isn’t some hard line, it may vary but the average is 40% as per HumanLayer’s workflow.
The Three Phases
The goal is to build around ‘Context Window’ so the workflow starts from.
Research → Plan → Implement
Each phase is designed to keep the next one lean.
Research = Compression of Truth
Research isn’t about understanding the whole codebase. It’s about compressing exactly what the agent needs for the specific task — and nothing else.
The rules for this phase are strict:
- Understand how the affected area of the system works
- Find the relevant files
- Stay objective — no bug hunting, no implementation opinions
The output is a research.md — 300 to 1000 lines of compressed, objective truth extracted from the actual code. Not from documentation. Not from memory. From the source files themselves.
Memento (The Movie) analogy here, and it stuck: the agent wakes up with no memory. If you don’t onboard it properly, it makes things up — filling gaps with plausible-sounding patterns from training data that have nothing to do with your system.
The research phase is how you stop that. You hand the agent a snapshot of exactly what’s true before it touches anything.
Plan = Leverage
The input to the planning phase is research.md from the previous step. The output is a plan.md:
- Exact implementation steps
- Filenames, line numbers, code snippets
- Testing steps, explicit
- Checkboxes the agent marks off as it worksThe plan serves two purposes. One: it gives the agent a concrete map, not a vague directive. Two: it’s the review artifact that actually gets read.
I can read 300 lines of plan.md. I cannot meaningfully review 1,000 lines of Dart or Go in a pull request — I’ll skim and miss things. Catching a problem at the plan stage costs one conversation. Catching it post-implementation costs a rework cycle.
If the plan is good, that’s enough.
This is also what concept - harness engineering calls mental alignment — keeping everyone calibrated on what’s being built without needing to read every diff. The plan is the shared artifact. The implementation becomes almost a formality.
Implement = Stay Smart
If the research is solid and the plan is right, implementation is almost boring. The agent follows a clear map. Context stays lean. Results are predictable.
HumanLayer ships implementation instructions that read less like a prompt and more like a process contract:
Plans are carefully designed, but reality can be messy. Your job is to:
- Follow the plan's intent while adapting to what you find
- Implement each phase fully before moving on to the next
- Verify your work makes sense in the broader codebase context
- Update checkboxes in the plan as you complete sectionsThey tested this on a 300,000-line Rust codebase. The PR merged. No review notes. That result came from the process, not the model.
The Gap in My Own Workflow
My current workflow already looks like this:plan → execute → document. I’ve been doing something close to what most recommended teams described.
But two parts landed as a gap.
Research and relying on my docs/ as the agent’s primary source of context — the architecture files, the CLAUDE.md, the module-level docs. The agent reads them and trusts them. The problem is docs go stale. The code doesn’t. Even tough we have techniques like doc-gardening recommended by OpenAI but still, doc’s SHOULD NOT be the source of truth. They should act as navigator for the agent.
If you keep relying on the docs as source of truth you’ll end up just writing more and more lines of code, plain text and comments to maintain.
The research phase fixes this. Instead of loading static docs every session, you run an on-demand research agent that reads the actual source files and returns a fresh research.md specific to the task at hand:
/research_codebase I'm implementing a new feature related to notifications
— can you tell me everything about how the notification system works today?The agent reads the code, uses the docs to navigate to it. The research.md it returns is a snapshot of what’s actually true, right now.
That’s the shift I’m working toward.
The One Thing That Doesn’t Change
“You can’t outsource your understanding.”

Not thinking, specifically — understanding. The hard work of knowing how a system is designed, what constraints it operates under, why something was built a certain way. An agent can amplify that understanding. It cannot replace it.
If the research is vague, the plan will be vague. A bad plan produces a lot of bad code. By the time you see it in a PR, the cost is high.
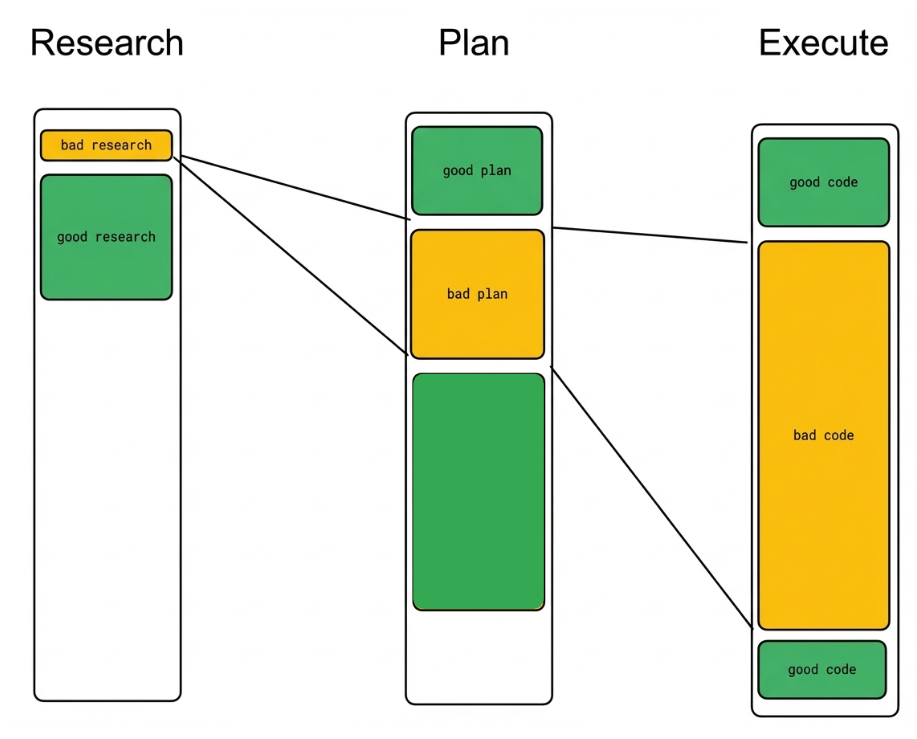
Ref: Mashood Rastagar’s Advanced Context Engineering
The leverage point is at the front — in how you frame the research, in how carefully you review the plan. That’s where the human effort belongs. Not in reviewing diffs at the end and hoping the agent didn’t miss something.
Conclusion
By focusing on what goes into the agents (as tokens) we can leverage the correct output. We shouldn’t be relying on the models capabilities rather we should focus on the improving our configuration around them. So if you zoom out a little bit you’ll realize by managing context window in better way, you’re doing a lot with current capabilities for the LLMs available.
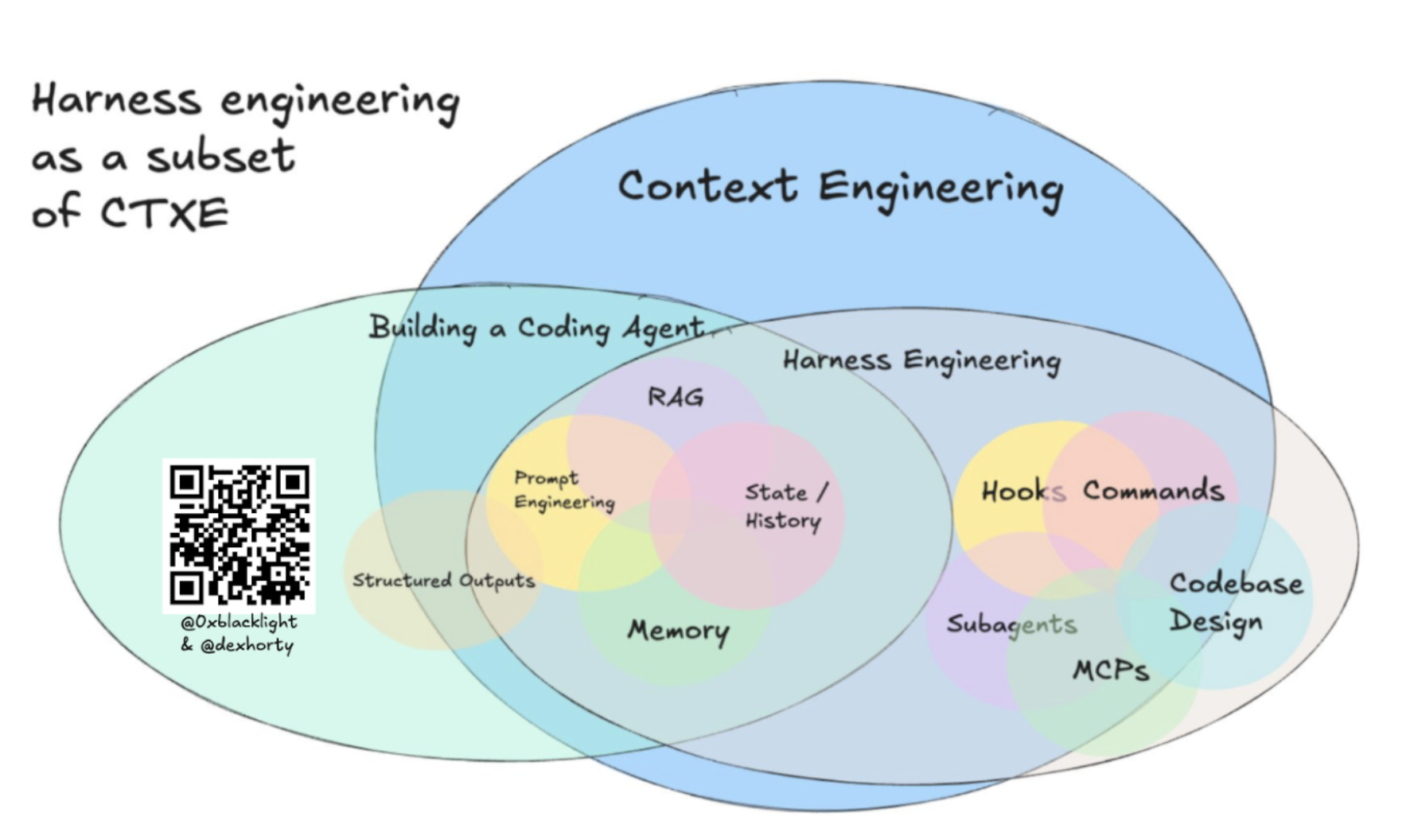
This post builds on Harness Engineering - Rethinking AI, which covers the scaffolding around the agent. Context engineering is what you feed into that scaffolding.